
I förra inlägget talade jag om de tre nivåerna inom medicinsk kunskap och om att det mest produktiva området för framtida utveckling av journalsystem antagligen är i nivå 2 (enligt min indelning i tre nivåer).
Som exempel på ett renodlat verktyg i nivå 2 gav jag en presentation av ett fiktivt system jag kallade Q.E.D. i brist på bättre. (Det spelar mindre roll vem jag gav presentationen till, men här är den i alla fall.)
För att påminna om vad “nivå 2” betyder i sammanhanget: ett verktyg som inte har någon bindning till patientens individuella information och inte heller till kunskapsbasen. Dvs ett verktyg som helt och hållet förbättrar och förstärker en metodologi. Och det tycker jag “Q.E.D.” är ett utmärkt exempel på. Som sagt finns det inget sådant i nuvarande journalsystem, inte vad jag känner till i alla fall, men det borde det nog göra.

Dagens journalsystem ses av somliga som perfekta och av andra som högst bristfälliga. Oftast är de system läkare gillar samtidigt ogillade av administratörer och omvänt. Visst vore det coolt att hitta på ett system båda grupper gillar, eller hur?
Låt oss först se vad journalsystemen ur läkarens synvinkel gör bra och vad de gör dåligt. Allt vad som handlar om patientens historia funkar i allmänhet rätt bra. Vad som handlar om vad man ska göra härnäst med patienten är däremot oftast rätt skralt.
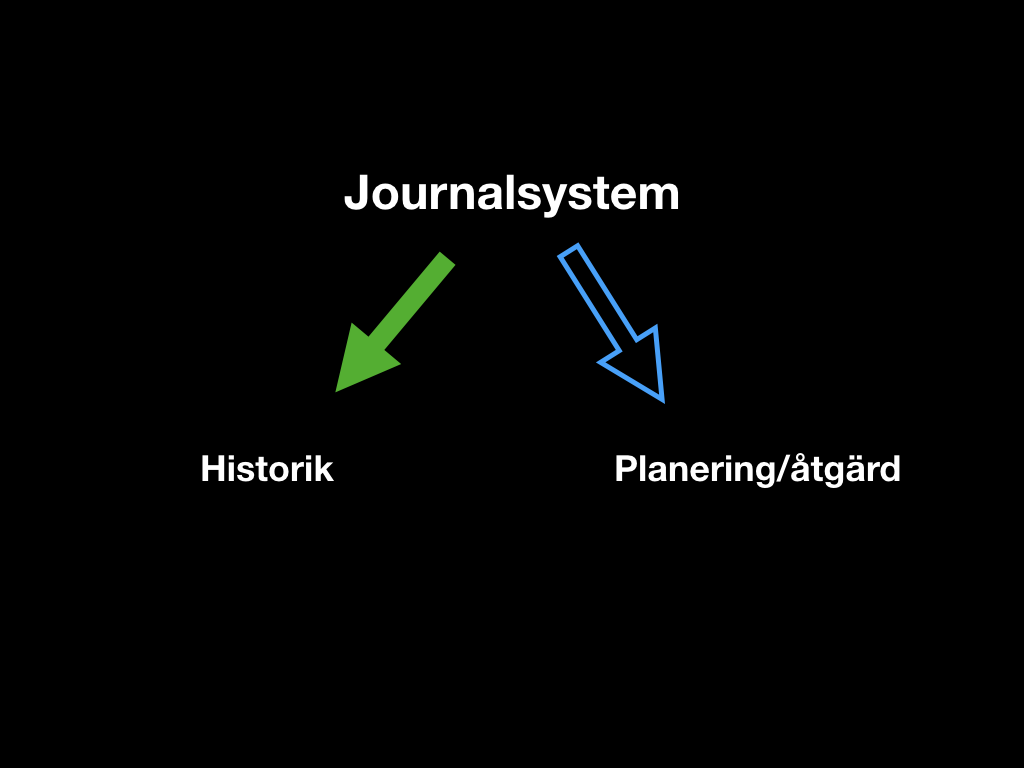
I den välfungerande historikdelen finner man notat, remissvar, labbsvar, röntgensvar, läkemedelslista och utfärdade intyg av alla dess slag. Mao, vad som redan hänt kan man oftast återfinna. Ibland efter en hel del letande, men låt oss vara generösa och säga att det här är bra.

Men när man kommer till att skapa nya ordinationer, röntgenbeställningar, hitta och fylla i formulär och rätt sökordsmallar så blir det en ostrukturerad soppa. Systemet har inte den blekaste aning om vad man som användare håller på med och presenterar alltså helt ofiltrerade och osorterade val.
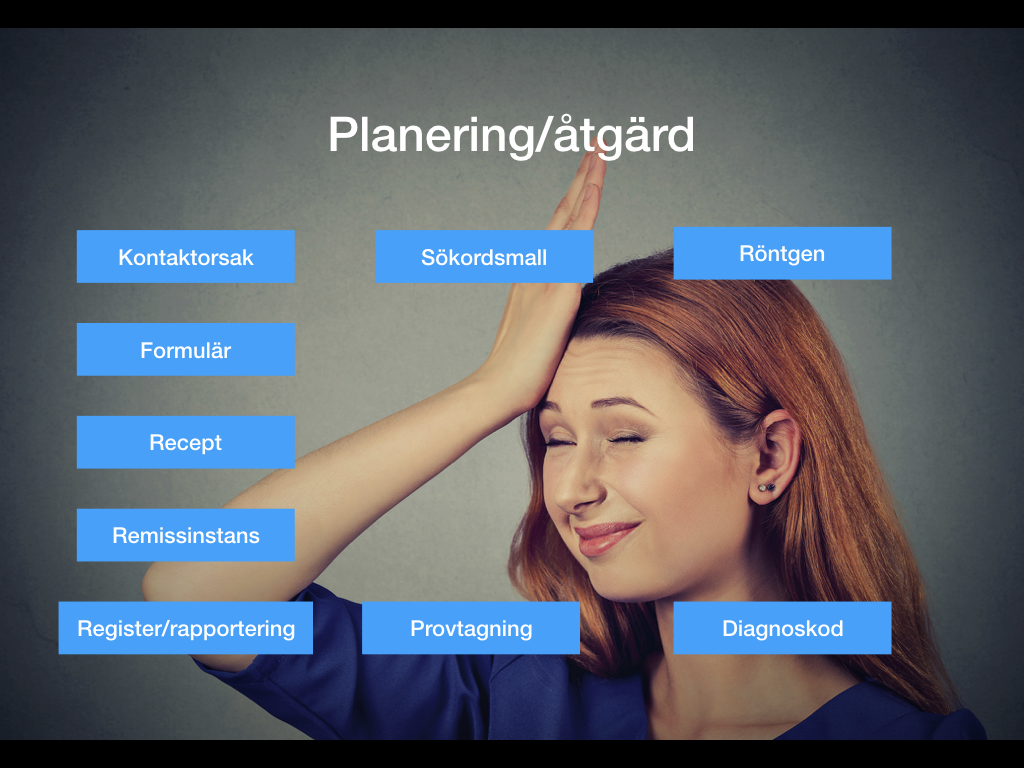
Låt oss med hjälp av exempel definiera problemet lite tydligare.

Föreställ dig att du som läkare har en patient som kommer med kontaktorsaken (problemet) “huvudvärk” och att du vill remittera denna patient eftersom du misstänker att det kan ligga något allvarligt bakom. Du öppnar remissmodulen i journalsystemet och får följande lista presenterad (se figur). Det enda icke helt befängda valet i listan nedan är ju neurologen. Ingen av de övriga valen verkar vettiga, allra minst kirurgen (ni som läst Richard Fuchs vet vad jag menar). Men ändå får jag vada igenom hundratals remissinstanser för att välja rätt.
Det finns värre exempel. Tänk dig ett systoliskt blåsljud på hjärtat på ett barn. Ska det till barnmottagningen? Kardiologen? Eller finns det en barnkardiolog gömd på barnmottagningen eller kardiologen eller nån annanstans? Oftast kan man inte ens få reda på det via den här listan utan får springa runt och fråga kollegor eller sekreterare.

Ett annat exempel: en patient har kontaktorsaken “sömnbesvär” och jag söker i dokument och får en lista liknande denna. Hur sannolikt är det att jag behöver ett dödsbevis (redan nu)? Men ändå står det där tillsammans med vård av barn och infektioner. Det gör det ju inte lättare att hitta rätt, precis.

Hur löser vi det, då?

Som exempel på lösningen väljer vi ett öronbarn. Föreställ dig att vi nu behöver välja medicinering och då i synnerhet antibiotika. Så läkaren går in på läkemedelsmodulen och fyller antingen i namnet på lämpligt antibiotikum ur minnet, eller väljer ur en alfabetisk lista som innehåller tusentals produkter. Alldeles för många för att bara skrolla igenom.
Trots att vi alltså har fyllt i kontaktorsak “ÖNH” eller “öron”, så presenterar systemet oss antivirala medel, medel vid HIV, psykiatriska medel, p-piller, antidiabetica, slemlösande och, i det här exemplet, ett enda möjligt antibiotikum (men inte förstahandsvalet).

Relevanta antibiotika finns alltså utspridda och gömda genom hela listan. Svårfunnet är bara förnamnet.

Vad vi borde fått presenterat istället är de mest sannolika valen först i listan, följt av resten. På så sätt ser man direkt de produkter man oftast använder, men har man fortfarande möjligheten att välja ur hela listan om det behövs.

Hur fixar vi att de mest sannolika valen kommer först?

Först och främst organiserar vi allt under “kontaktorsaker”. Dvs, för varje kontaktorsak finns ett urval av läkemedel, remisser, labbprover, etc. Kontaktorsaker bör vara lagom specifika. T.ex. “ÖNH” eller “öronvärk” är alldeles utmärkt nivå av specificitet. Systemet själv kan dra slutsatsen att det är ett barn/vuxen, kvinna/man, pre/postmenopausal och gör det lite mer specifikt på så sätt. En annan viktig parameter är yrkesgrupp (läkare, sköterska, sjukgymnast, psykolog, etc), eftersom valda åtgärder för en viss kontaktorsak kommer att vara helt olika1.
För en viss kontaktorsak håller systemet reda på hur ofta en viss produkt eller remiss (eller labb, röntgen, etc) används och sorterar de mest använda valen först. Dvs att om systemet ser att Kåvepenin, Abboticin, Ery-Max, Amoxicillin ofta skrivs ut när kontaktorsaken är “öronvärk”, så kommer systemet att presentera dessa antibiotika nästa gång man har en patient med kontaktorsaken “öronvärk”.
Förmodligen vore det lämpligast att denna rankning sker över ett antal läkare som grupp, t.ex. en avdelning, vårdcentral eller region. Det gör ju att nya läkare automatiskt leds in i banor som motsvarar “gängse behandling” utan att tvingas till det. Den terapeutiska friheten finns ju kvar tillsammans med möjligheten att anpassa sig till patientens egenskaper och val.
Varje läkare kan själv välja produkter han/hon vill se överst genom att markera som “favorit”, även om dessa inte används i tillräcklig omfattning för att automatiskt hamna högt upp i listan.
Till slut finns ju också möjligheten att på departement eller regionnivå flagga upp rekommendationer om man snabbt vill få upp ett specifikt val högt i listan för en viss kontaktorsak.
Notera att en intressant möjlighet är också att förse vissa ordinationer eller remisser/röntgen/labbeställningar för vissa kontaktorsaker med en varning eller textbox. Till exempel om man vill påpeka att en viss röntgenundersökning inte längre anses lämplig vid en viss frågeställning. Sedär kunskapsspridningen!

Egenskaperna i systemet är intressanta.

I första rummet kommer “självlärande”. Alldeles för många system som har med kunskap att göra i dagens sjukvård faller på att de måste konfigureras och förses med enorma mängder data innan de blir användbara, samt att de snabbt måste kunna anpassas vartefter. Det funkar inte annat än i undantagsfall. Q.E.D. är helt självlärande och behöver ingen konfigurering alls. Jo, en grej: en vettig lista på kontaktorsaker behövs.
Det självlärande systemet kan påverkas vid behov med egna favoriter och med rekommendationer, men inget av dessa behövs innan systemet blir användbart. Favoriter och rekommendationer berikar systemet vartefter, men är alltså optionella.

Sen finns det några naturliga följder (“emergent properties”) av detta:
Läkare och sköterskor blir påminda vilka de mest gångbara och korrekta åtgärderna är, vilket gör vården mer konsistent, utan att det läggs på som ett tvång. Flexibiliteten för anpassning till den individuella patienten finns oantastat kvar.
Eftersom sökordsmallar också anpassar sig efter de mest använda sökorden för varje kontaktorsak så kommer man påminnas om de kliniska data som oftast förekommer i dessa situationer och därmed blir data mer fullständiga för rapportering och analys.
Möjligheten att lägga in rekommendationer samt varningar kopplade till alla dessa element och per kontaktorsak gör att man snabbt kan få ut nya råd och rön till rätt personer och på det ögonblick de träffar just den typen av patient som råden och rönen gäller. Dvs kunskapspridning på rätt nivå, rätt ögonblick och rätt plats.

I Q.E.D. systemet finns för ovanlighetens skull element som borde glädja alla tre involverade grupper, nämligen vårdpersonalen som kan göra ett snabbare, trevligare och bättre jobb, administratörerna som kan sprida information snabbare och mer riktat, och få bättre strukturerad information tillbaka, samt inte minst patienterna som blir snabbare, fullständigare och korrektare behandlade.

What’s not to love…

(Alla bilder från iStockphoto.com)